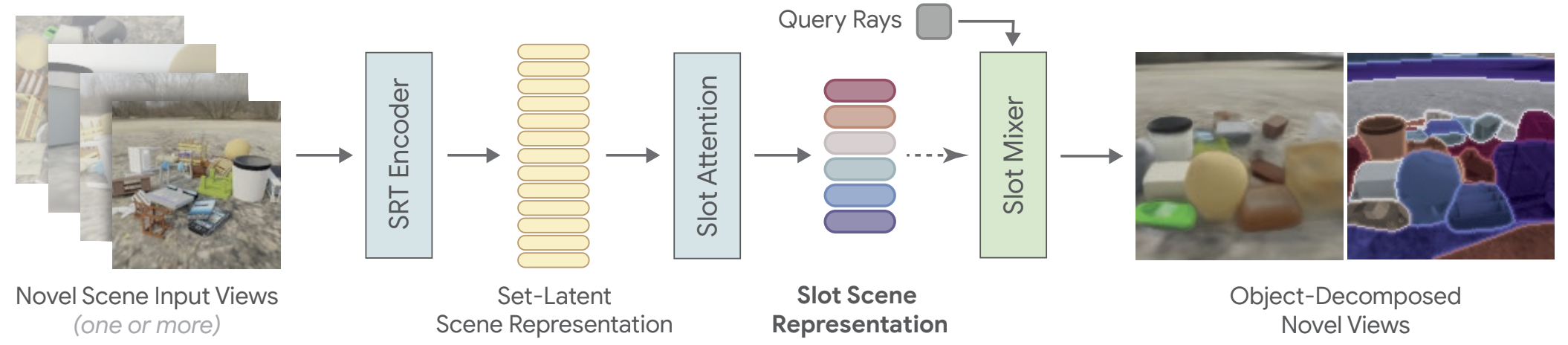
Object Scene Representation Transformer
Mehdi S. M. Sajjadi‡,
Daniel Duckworth*,
Aravindh Mahendran*,
Sjoerd van Steenkiste*,
Filip Pavetić,
Mario Lučić,
Leonidas J. Guibas,
Klaus Greff,
Thomas Kipf*
![]()
NeurIPS 2022
‡correspondence to: osrt@msajjadi.com
*equal technical contribution